一个大致的印象
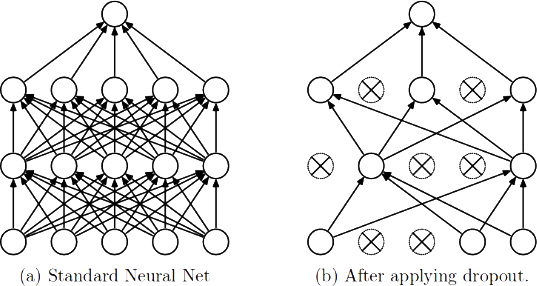
关于 Dropout,我们都知道它是一种强大的正则化技术,通过在训练时随机“丢弃”一部分神经元来防止过拟合。但如果再往下深究一层,它究竟是如何起作用的?我觉得,最深刻也最优雅的解释是:Dropout 本质上是在训练一个共享权重的、由海量子网络构成的集成模型(Ensemble)。
要真正理解这个观点,我认为关键在于抓住“子网络”和“共享权重”这两个概念。
我们可以这样想象:一个拥有 N 个神经元的全连接层,理论上可以衍生出 种不同的神经元激活模式。每一种模式,其实都对应着一个从原始“父网络”中“采样”出来的、结构更精简的“子网络”。
在训练的每一步,Dropout 所做的,就是随机选择其中一个子网络来进行训练。这带来了一个非常有趣的问题:这成千上万、甚至数以亿计的子网络,难道是独立训练的吗?当然不是,那样的话计算开销是无法承受的。
这里的奥妙就在于权重共享。所有 个潜在的子网络,都并非独立的实体,它们都源自于同一个父网络,因此共用着同一套权重参数。当某个子网络在一次迭代中被激活并训练时,其所包含的连接权重会得到更新。而这个更新会直接作用于父网络的全局权重之上。
这意味着,上一个子网络学到的“知识”,会通过共享权重传递给下一个被随机采样到的子网络。这是一种极为高效的集成训练方式,用一个模型的训练开销,近似达到了训练海量模型的目的。
理解了这种“共享权重的子网络集成”机制后,Dropout 为何能有效正则化、提升模型泛化能力,也就变得顺理成章了。其核心效果,就是打破了神经元之间脆弱的协同适应。
在没有 Dropout 的网络中,神经元之间很容易形成复杂的依赖关系。比如,神经元 A 的输出可能恰好能修正神经元 B 的一个微小错误。这种“你犯错,我来补”的模式,会让模型在训练集上表现得很好,但这种局部的高度耦合在面对新数据时往往非常脆弱,这是过拟合的一种表现。
而 Dropout 的存在,则无情地打破了这种“小团体”。
- 强迫独立:由于任何一个神经元都可能在下一次迭代中被随机“丢弃”,神经元 A 就无法再稳定地依赖神经元 B 来为自己“打补丁”,因为“队友”随时可能不在场。
- 学习普适特征:为了在任何随机组成的“临时团队”里都能做出有价值的贡献,每个神经元都被迫去学习那些自身就足够强大、不依赖于特定上下文的普适性特征。好比说,一个视觉神经元可能会发现,与其学习如何跟其他神经元配合来识别“猫脸”的某个特定区域,不如直接学习去识别“猫眼”或“猫胡须”这种更具迁移性的、独立的特征。
最终,经过这番“历练”,网络中的每个神经元都趋向于成为一个更加独立和鲁棒的特征检测器。整个网络因此变得更加“健壮”,不再轻易地被训练数据中的噪声和偶然性所迷惑,泛化能力自然也就得到了提升。
数学操作
在训练时,Dropout 会以概率 p 将某些神经元的激活值 h 置为零,并将其余未被关闭的神经元激活值拉伸 倍。
这个拉伸操作的目的是保持激活值的期望(均值)在训练和测试时不变: