下面是课程笔记,还没有任何整理,就先这样放着吧,后面有时间再整理 action value 其实跟贝尔曼公式的推导没什么区别 迭代
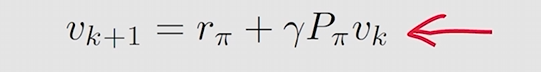
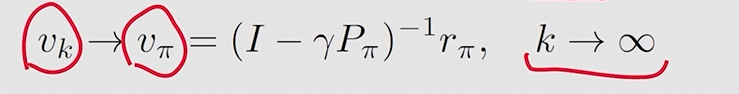
 以上公式证明介绍了为什么k→无穷, 趋向于 , 但是我们也只知道了一个 呀,正常一个状态空间里应该有n个V才对呀
以上公式证明介绍了为什么k→无穷, 趋向于 , 但是我们也只知道了一个 呀,正常一个状态空间里应该有n个V才对呀
anyway,我们已经能求解状态空间的各个 s的得分了,评价策略
action value就是s和a都确定情况下的贝尔曼公式
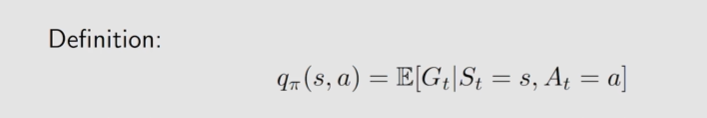
 贝尔曼最优公式 -一个特例
贝尔曼最优公式 -一个特例
更新policy ,用action value最大的策略
迭代actionvalue得到最优策略
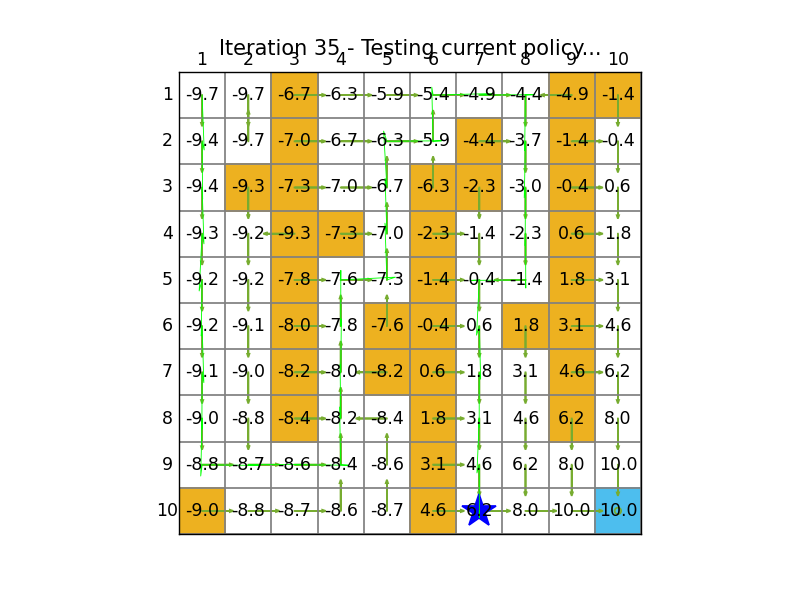 这个迭代的过程中,我发现actionvalue竟然是从target逐渐向 src开始扩散的,正常情况系下我们不是应该不知道target在哪才对
这个迭代的过程中,我发现actionvalue竟然是从target逐渐向 src开始扩散的,正常情况系下我们不是应该不知道target在哪才对
action value 的计算会被policy影响吗?肯定的呀我想什么呢,公式后半部分都带 了 所有state value都比其他策略大
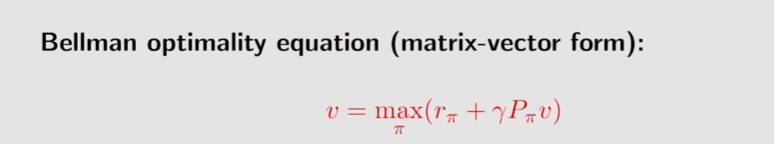 如何用贝尔曼最优公式理解迭代action value 就能拿到最优策略的这个过程?
如何用贝尔曼最优公式理解迭代action value 就能拿到最优策略的这个过程?
 fixed point/contraction mapping theorem
fixed point/contraction mapping theorem

上面说的这个理论 实际上贝尔曼最优公式就符合它的应用条件
v = f(v), 并且还有一个fixed point,那就是?好吧其实我不知道
但是反正这个fixed point最后就是这个最优的策略

value iteration/policy iteration algorithm
(truncated policy iteration) 如何用value iteration去找最优策略
value iteration
随意设定一个初始 ,然后计算 ,这样就能用一个贪婪策略更新 ,简单来说就是取qk最大的方向,将s下的action的概率为 1,基于这个 来更新 ,大致这么理解,最后其实就是取最大的qk作为vk+1
policy iteration
感觉就是将valueiteration的顺序换了一下,先估计一个 然后算出v, 用v去迭代出 , 如此循环,还是建立在contraction mapping theorem上的